Data Modelling
In the following section, you will find all the necessary information to design your own data model.
You should have read the White Paper Data In Pryv which outlines how pryv.io manages data and why we designed it this way.
Please be aware that this guide is NOT intended to be read cover to cover (read Clean Code from Uncle Bob instead), but rather to be used as a training manual to assist you in designing your data model.
The general introduction describes Pryv.io data modelling conventions to help you understand how you should build your own data model. Then we provide you with a broad range of use cases that you can encounter while building your data model.
Table of contents:
- 0 References
- 1 Introduction
- 2 Declare the stream structure
- 3 Avoid event types multiplication
- 4 Define a custom event type
- 5 Share a single event
- 6 Handle multiple devices
- 7 Reference events
- 8 Store technical data from devices
- 9 Define accesses to the streams
- 10 Perform an access delegation
- 11 Store data accesses
References
- White Paper - Data In Pryv)
- Template Excel document for Allergen Data Model)
- API Reference
- Event types Reference
- Event types Github repository
- Access data structure
- Batch call
*To savour fresh and in moderation.*

Introduction
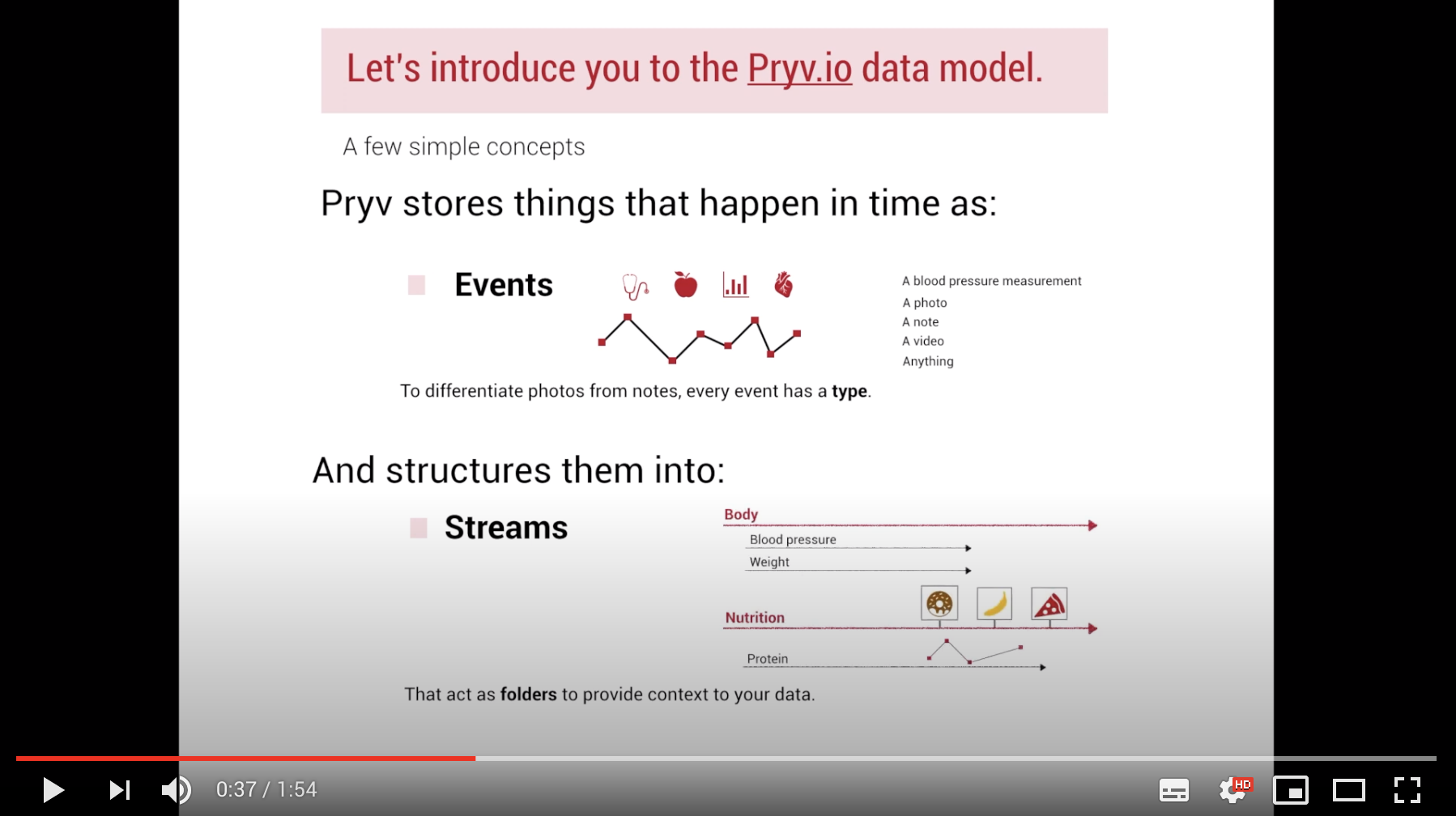
Data in Pryv is organized in “streams” and “events”. Ok, hold on. What are “Streams” ?
- Streams are the main way of encoding context for events. They act as folders in a file system (“Health”, “Geolocation”, etc), and follow a tree structure with multiple roots.
And what are “Events” ?
- Events are the primary unit of content in Pryv.io. They are similar to files that are inserted in their corresponding folders. An event is a timestamped piece of typed data (e.g a weight measurement would have the type
mass/kg), and belongs to one or multiple streams. It can either have a type from the list of standard event types or a custom type that can be created for the intended use case.
Be patient, it is going to become crystal-clear for you with this video :
Now that you are getting familiar with the concepts, let’s go through a practical example.
Let’s suppose that your app, “Best Health App”, enables your user to track his health metrics and his physical activity using a smartwatch. A simple way to model his data would be to use two streams, “Health Profile” and “Smartwatch”:
- “Health Profile” corresponds to the health metrics of the user, with for example, the sub-streams “Height” and “Weight” in which, as you can guess, the height and weight measurements are respectively added (events of type
length/cmandmass/kg). - “Smartwatch” contains the collected data from the smartwatch. It can be for example the geolocation of the user in the stream “Position” (
position/wgs84events), the stream “Energy-intake” (positively correlated with the number of burgers your user has eaten during the day) and the stream “Energy-burnt” (corresponding to attempts to burn this fat), both containingenergy/calevents.
The stream structure of this data model can be visually represented as below:

This stream structure allows you to:
- combine different types of data (attachments, notes, health records, pictures, videos) coming from different data sources
- contextualize your data into an organization similar to folders
- control on a granular level access permissions to the data
Different permissions can be defined for each stream and substream, therefore enabling to share only the necessary information with third-parties (doctors, family, apps, etc). If multiple actors are involved in the process, this allows to precisely control the access level to the different streams. So that your grandma doesn’t have a heart attack when looking at your stream “Weight” if you don’t allow her to do so.

In the example above, access to particular streams of data can be restricted:
- the Best Health App has a
manageaccess on the streams Position and Energy, and areadaccess on the streams Height and Weight - the Dietetician has a
readaccess on the stream Energy, Height and Weight
Available levels of permissions (read, manage, contribute, create-only) are defined and explained here under permissions.
Declare the stream structure
In the beginning was the Event, and the Event was in the Stream.
Here is your starting point.

Building your own data model means defining your streams and events structure following this template document. Such a document serves as reference for the potentially multiple actors that will implement apps for a single Pryv.io platform.
The Allergen data model on which the document is based is described in the stream structure below. The smartwatch collects geolocation data from the user, which is used by the Allergen Exposure app to compute ther user’s daily exposure to allergens:

N.B.: The User’s beard is for illustrative purposes solely. However you can check here what the American Lung Association thinks about the association between beard and allergy.
Now that your data model is set, you need to declare the stream structure at each user account creation on Pryv.io. Sounds like lots of work. Well, luckily, we thought about it: you can do it all in one call by using a batch call.
Let’s take the previous stream structure :
├── Smartwatch
│ └── Position ("position/wgs84" events)
├── Allergen Exposure App
│ ├── Pollen ("density/kg-m" events)
│ ├── Cereal crops ("density/kg-m" events )
│ └── Hazelnut tree ("density/kg-m" events )
└── Health Profile
├── Digital tensiometer
│ └── Blood pressure ("blood-pressure/mmhg-bpm" events)
└── Weight ("mass/kg" events )
To add a position/wgs84 event in the stream “Position”, two options are available:
- Use the “try and fail” method (recommended)
res = events.create({"streamIds": ["position"] ...})
if (res.error.id == "unknown-referenced-resource") {
batchCall([
streams.create({"id": "smartwatch", ...}),
streams.create({"id": "position", ...}),
events.create({"streamIds": ["position"] ...})
])
}
You try to add your event(s) in the desired stream, and if it fails you create the stream structure.
- Create the whole stream structure before adding the event in the concerned stream (long and tedious)
[
{
"method": "streams.create",
"params": {
"id": "smartwatch",
"name": "Smartwatch"
}
},
{
"method": "streams.create",
"params": {
"id": "position",
"name": "Position",
"parentId": "smartwatch"
}
},
{
"method": "events.create",
"params": {
"streamIds": [
"position"
],
"type": "position/wgs84",
"content": {
"latitude": 40.714728,
"longitude": -73.998672
}
}
}
]
Avoid event types multiplication
Everything should be made as simple as possible, but not simpler.
- Albert Einstein
This is what we had in mind when designing our data model in streams and events. Streams should provide the necessary context to events, so that the meaning of events can be directly understood from the stream they are in. Simple.
The number of different event types should therefore be minimized, unlike the number of different streams that should be maximized. Not simpler.
Let’s illustrate it. Grandma needs to record her daily medication intake (daily consumption of paracetamol, spasfon and levothyrox in mg). Two options are available to organize her stream structure:
1. Create an event-type per medication (not recommended)
├── Medication
│ ├── Intake ("paracetamol/mg", "spasfon/mg", "levothyrox/mg" events)
│ └── ...
An intake of 500mg of paracetamol will be recorded this way:
{
"method": "events.create",
"params": {
"streamIds": ["intake"],
"type": "paracetamol/mg",
"content": 500
}
}
The problem is… Every time Grandma will need to add a new medication in her daily cocktail (and God knows she will, she’s not getting younger), we will have to create a new event type to perform content validation. The detailed steps are explained in the Data Types Github repository.
2. Create a substream per medication (recommended)
├── Medication
├── Paracetamol ("mass/mg" events)
├── Spasfon ("mass/mg" events)
└── Levothyrox ("mass/mg" events)
An intake of 500mg of paracetamol will be recorded this way:
{
"method": "events.create",
"params": {
"streamIds": ["paracetamol"],
"type": "mass/mg",
"content": 500
}
}
This solution has the advantage of resolving the forementioned problem by providing an easily adaptable structure. Every time Grandma needs to add a new medication to her cocktail, we only need to create a new stream.
As there is no limit to the number of substreams to a stream, it’s only Grandma’s health, incidentally.

In this regard, multiplying the number of streams is a preferable solution when you need to enter data measurements for different types of components (e.g medications, diseases, medical devices, etc).
Define a custom event type
Time to get our hands dirty.
If your event type is not referenced in the default Event Types list, you can create your own.
Does it mean you can create absolutely any event type you want? Well, not exactly. It will need to follow the specification {class}/{format} (e.g note/txt). Events with undeclared types are allowed but their content is not validated. You can find more information on this in the corresponding section.
For example, let’s say that you need to create a custom event type for your 12-lead ECG recording ecg/12-lead-recording. If you want to perform content validation and ensure that every time you retrieve a new event it has the right structure, the procedure is the following:
- Fork the Data Type Github repository
- Define your event type in a JSON file, in this case
ecg.jsonfile:
{
"ecg": {
"formats": {
"12-lead-recording": {
"description": "Conventional 12-lead ECG measuring voltage with ten electrodes.",
"type": "number"
}
}
}
}
- Validate the JSON schema of your event type
- Publish these files on a webserver and indicate the
flat.jsonfile in the platform parameters :
EVENT_TYPES_URL: "https://pryv.github.io/event-types/flat.json"
The detailed steps can be found here.
Share a single event
Sometimes, your user might need to share a single event (and not a whole stream) with third parties. Pryv.io allows you to store an event in one or multiple streams, wich can facilitate the sharing of particular events.
How so ?
Let’s take the example of your Grandma (again). She is storing her blood analysis results in a substream “Blood” under her “Health” profile. She usually shares the whole stream with her hematologist, but now she only needs to share her last blood analysis with her general practitioner.

To do so, you can create a stream “Sharings” reserved for the data sharings she will need to do with third parties. You can then store her last blood analysis in a sub-stream of the stream “Sharings” that you will share with her doctor.
├── Health
│ ├── Blood ("file/attached" events: 'blood-analysis-may', 'blood-analysis-july' events, etc)
│ └── ...
└── Sharings
├── Blood Sharing ("file/attached" event corresponding to the last blood analysis, e.g 'blood-analysis-july' event)
└── ...
You can then create an access for her doctor on the stream “Blood Sharing”:
{
"method": "access.create",
"params": {
"type": "shared",
"name": "For Grandma's doctor",
"permissions": [{
"streamId": "blood-sharing",
"level": "read"
}]
}
This method allows to share particular events (e.g the “blood-analysis-july” event) with third parties, while retaining the original event in another stream.
Handle multiple devices
Forget about the good old times when we would have one fixed-line telephone per building, and you’d have to climb to the last floor to tell your neighboor John to answer the phone (who forgot his keys again at his mum’s place).

Now, John not only has his own smartphone and smartwatch, but even a smart key chain to help him retrieve his keys.
So how to model John’s data coming from multiple devices ?
Let’s list all the possible data sources for John:
- a Smartwatch that collects his pulse rate and temperature during his sleep (
frequency/bpmandtemperature/cevents) - a Sleep Control Mobile App that controls the sleep quality using data from the smartwatch (
sleep/analysisevents) - a Smart key chain that tracks the geolocation of John’s keys at any time (
position/wgs84events)
One general advice is to use one stream or substream per device. Each event can be stored across one or multiple streams: this enables you to save an event, e.g a sleep/analysis event, in both streams Sleep Control Mobile App and Health to contextualize the event.
Given this situation, we would recommend a stream structure similar to the following:
├── Health
│ ├── Sleep ("sleep/analysis" events)
│ ├── Heart rate ("frequency/bpm" events)
│ ├── Height ("length/cm" events)
│ └── Weight ("mass/kg" events)
├── Smartwatch
│ ├── Temperature ("temperature/c" events)
│ └── Pulse ("frequency/bpm" events)
├── Sleep Control Mobile App
│ └── Sleep quality ("sleep/analysis" events)
└── Smart key chain
└── Geolocation ("position/wgs84" events)
This allows you to easily retrieve all events related to one device (e.g “Smartwatch”). The events.get call:
{
"method": "events.get",
"params": {
"streamIds": [ "smartwatch"],
}
}
The result:
{
"events": [
{
"id": "ckdfruqua000z7ppvzspqsnyz",
"time": 1596531629.026,
"streamIds": ["pulse", "heart-rate"],
"type": "frequency/bpm",
"content": 85,
"created": 1596531629.026,
"createdBy": "ckdfruqs700047ppvzjoxu1jo",
"modified": 1596531629.026,
"modifiedBy": "ckdfruqs700047ppvzjoxu1jo"
},
{
"id": "ckdfruqua000v7ppv37k7gokc",
"time": 1596341634.567,
"streamIds": ["pulse", "heart-rate"],
"type": "frequency/bpm",
"content": 90,
"created": 1596341634.567,
"createdBy": "ckdfruqs700017ppvj4rci1cg",
"modified": 1596341634.567,
"modifiedBy": "ckdfruqs700017ppvj4rci1cg"
}
]
}
At the same time, events related to the device can also be stored in other streams of data to be placed in the necessary context (e.g “Health”).
The events.get call:
{
"method": "events.get",
"params": {
"streamIds": [ "health"],
}
}
The result:
{
"events": [
{
"id": "ckdfruqua000z7ppvzspqsnyz",
"time": 1596531629.026,
"streamIds": ["pulse", "heart-rate"],
"type": "frequency/bpm",
"content": 85
},
{
"id": "ckdfruqua000v7ppv37k7gokc",
"time": 1596341634.567,
"streamIds": ["pulse", "heart-rate"],
"type": "frequency/bpm",
"content": 90
},
{
"id": "cfgtrzqua999f7ppv45g3zuit",
"time": 1596341634.567,
"streamIds": ["weight"],
"type": "mass/kg",
"content": 88
},
{
"id": "cghztrwfs345r3llk3j69port",
"time": 1596341634.567,
"streamIds": ["height"],
"type": "length/cm",
"content": 185
},
{
"id": "crtkophui678t3plk37k7tzui",
"time": 1596341634.567,
"streamIds": ["sleep", "sleep-quality"],
"type": "sleep/analysis",
"content": "inBed"
}
]
}
Reference events
Some of your Pryv.io events may be calling one another, and you might need to reference events between themselves.

To do so, multiple options are available depending on your use case:
1. Keep memory of the raw data for a processed result
Let’s say that your Allergen Exposure app computes the allergen exposure (processed result) of your user John using his geolocation (raw data). You need to keep a reference to the original event (John’s geolocation), in case you want to test a different algorithm to compute his allergen exposure for example.
To do so, you can reference the raw data in the clientData field of your processed result.
John’s raw event (geolocation):
{
"id": "ckd0br289000o5csm15xw6776",
"time": 1595601190.665,
"streamIds": ["geolocation"],
"type": "position/wgs84",
"content": {"latitude": 40.714728, "longitude": -73.998672}
}
The processed result from your algorithm:
{
"id": "csh1rb4560567p5mst35sy9876",
"time": 1786234164.463,
"streamIds": ["pollen-exposure"],
"type": "density/kg-m3",
"content": 320,
"clientData": { "raw-event": {
"id": "ckd0br289000o5csm15xw6776"
}}
}
The field clientData enables you to reference the event from which the processed result is originating and to make references across different events.
2. View data jointly
Grandma went to do an ECG recording on Monday morning.
{
"id": "ckdfruqua00127ppvue8jwrpk",
"time": 1350373077.359,
"streamIds": ["ecg"],
"type": "ecg/6-lead-recording",
"content": {...},
}
She usually tends to forget what happened to her earlier in the day. Did the doctor take her blood pressure, or her weight along with the ECG recording ? A solution to easily view all events related to her ECG recording is to artificially set the same “time” parameter for all events related to the recording.
So that if the ECG recording occured at “1350373077.359”, the weight measurement associated to the recording, the device parameters of the recording, etc, will have their “time” set to “1350373077.359”.
This allows to display all the events related to the ECG recording using the time reference:
- Set the same time reference for related events (here
1350373077.359) - Get all events occuring at the time
1350373077.359:
{
"method": "events.get",
"params": {
"fromTime": 1350373077.359,
"toTime": 1350373077.359
}
}
The result:
{
"events": [
{
"id": "ckdfruqua00127ppvue8jwrpk",
"time": 1350373077.359,
"streamIds": ["ecg"],
"type": "ecg/6-lead-recording",
"content": {...},
},
{
"id": "ckdfruqua00107ppv0xeriki2",
"time": 1350373077.359,
"streamIds": ["weight"],
"type": "mass/kg",
"content": 60,
},
{
"id": "ckdfruqs700017ppvj4rci1cg",
"time": 1350373077.359,
"streamIds": ["devices"],
"type": "ecg-device/parameters",
"content": {...},
}
]
}
This will allow you to retrieve all time-related events to the ECG recording of your grandma: the weight associated to the recording, the device associated to the recording, etc.
3. Make a query on different events
Again, Grandma went to do an ECG recording on Monday morning, and cannot remember the weight that was associated to her recording. How can you query it?
Pryv.io does not allow to filter events in the same way as a classic database when performing an “events.get” API call.
To get all the different events associated to the same event (here the ECG recording on 03.08.2020), we recommend to store all the references to these events in a dedicated stream, e.g “ECG-Session-20200803”.
Here we want to get the weight (mass/kg event) associated to the ECG recording (ecg/6-lead-recording event). A possible solution is to store these events in the dedicated stream “ECG-Session-20200803” in addition to their respective streams (“Weight” and “ECG-recording”).
The stream structure will look like the following:
├── Recording
│ └── ECG-recording ("ecg/6-lead-recording" event)
├── Health
│ ├── Weight ("mass/kg" event)
│ └── Heart rate ("frequency/bpm" event)
├── Devices
│ └── ECG-device ("ecg-device/parameters" event)
└── Sessions
├── ECG-Session-20200803 (any type of event related to the ECG recording)
└── ...
An events.get call on the stream “ECG-Session-20200803” will allow to retrieve all events related to the ECG recording on 03.08.2020:
{
"method": "events.get",
"params": {
"streamIds": ["ecg-session-20200803"]
}
}
Result:
{
"events": [
{
"id": "ckdfruqua00127ppvue8jwrpk",
"time": 1596531629.026,
"streamIds": ["ecg-recording", "ecg-session-20200803"],
"type": "ecg/6-lead-recording",
"content": {...},
},
{
"id": "ckdfruqua00107ppv0xeriki2",
"time": 1350309876.634,
"streamIds": ["weight", "ecg-session-20200803"],
"type": "mass/kg",
"content": 60,
},
{
"id": "czj2pk293847o5lsk35xw0987",
"time": 1350309856.321,
"streamIds": ["heart-rate", "ecg-session-20200803"],
"type": "frequency/bpm",
"content": 100,
},
{
"id": "ckdfruqs700017ppvj4rci1cg",
"time": 1350376789.789,
"streamIds": ["ecg-device", "ecg-session-20200803"],
"type": "ecg-device/parameters",
"content": {...},
}
]
}
This method allows you to store all related events to a measurement in order to facilitate the query. Grandma can continue to forget stuff, her Pryv.io account is here to remember.
All the aforementioned solutions can be used together to reference events across them, but some of them will be more suitable than others depending on the use case.
Store technical data from devices
You sometimes need to store technical data from devices you are collecting data with, as it can be considered “personal data” of your user (see here for more on personal data).
After years of bad habits and a countless number of cigarettes, John had a heart attack. Your smartwatch “HeartHealth” luckily detected it soon enough and John survived. However, he needs to undergo an MRI scan to check for possible damages. Along with his MRI scan analysis, you need to keep the technical data from the MRI device that was used.
Multiple options are available to store this data:
1. Create an allocated stream in John’s account (recommended)
You can create a custom event type mri-device/parameters to store technical parameters of the MRI device used during the scan, and add a new event containing the technical data in the stream “MRI-device” for each MRI scan.
├── Recording
│ └── MRI-recording ("mri/signal" event)
├── Devices
│ └── MRI-device ("mri-device/parameters" event)
└── Sessions
├── MRI-Session-XYZ (any type of event related to the MRI scan)
└── ...
The stream “MRI-Session-XYZ” will contain all references to the MRI scan “XYZ”, corresponding to all events related to the MRI scan XYZ (MRI signal, device parameters, etc).
An events.get call on the stream “MRI-Session-XYZ” will allow to retrieve the scan measurements and the device parameters of the session XYZ:
{
"method": "events.get",
"params": {
"streamIds": ["mri-session-xyz"]
}
}
Result:
{
"events": [
{
"id": "cghpoizut22456pkuio3ngvhu",
"time": 1532568969.321,
"streamIds": ["mri-recording", "mri-session-xyz"],
"type": "mri/signal",
"content": {...},
},
{
"id": "ctzoiubn234890ppvj3rci1gh",
"time": 1350376789.789,
"streamIds": ["mri-device", "mri-session-xyz"],
"type": "mri-device/parameters",
"content": {...},
}
]
}
2. Add it in the clientData field of the MRI scan
When creating the mri/signal event related to the measured MRI signal during the scan, you can add the technical MRI data in the clientData field as in the following example:
{
"method": "events.create",
"params": {
"streamIds": [ "mri-recording"],
"type": "mri/signal",
"clientData": {
"device-parameters":
{
"magneticField":"1.5",
"FOV":30,
"sliceThickness":5
}
}
}
}
3. Store in a separate account
The other solution you might be thinking of is : “What if we store all technical data in a dedicated “System” Pryv.io account ? This would keep only “useful” data in John’s account, while we could still have all technical data stored somewhere.”
If you don’t want to bother John with technical data by adding it in his Pryv.io account, well, you might have to do it anyways.
Indeed, keep in mind that John needs to be able to access it anytime if it is considered as “personal” data.
You will therefore need to define a shared access for John on this data…
Define accesses to the streams
Ready to take a deep dive right into the core of Pryv.io ?

The Pryv.io streams structure allows you to define granular accesses on data and to share only necessary information with different access levels (“read”, “manage”, “contribute”, “create-only”).
The data sharing is made on streams (acting as “folders” in your computer) instead of particular events (similar to “files”).
And this could prove very useful. Imagine a situation in which you want one person to access a particular folder of your data, but not the rest. You have moved away to university, starting a new life, but you want to reassure your mum by sharing with her your position anytime. However, you don’t want her to access your “Glucose” and “Weight” streams not to upset her.
This can be easily done with Pryv.io.
├── Health
│ ├── Glucose ("density/mmol-l" events)
│ └── Weight ("mass/kg" events)
└── Smartwatch
├── Position ("position/wgs84" events)
└── Heart rate ("blood-pressure/mmhg-bpm" events)
The data sharing involves two steps:
1. The access creation using the accesses.create method
{
"method": "accesses.create",
"params": {
"name": "For my beloved mum",
"permissions": [
{
"streamId": "Position",
"level": "read"
}
]
}
2. The access token distribution
The accesses.create method will create an access token to be shared with your mum to enable her to read data from your stream “Position”, and only this one (“token”: “ckd0br26e00075csmifuhrlad”):
{
"access": {
"id": "ckd0br26e00065csmktc33x11",
"token": "ckd0br26e00075csmifuhrlad",
"type": "shared",
"name": "For my beloved mum",
"permissions": [{"streamId": "Position", "level": "read"}],
"created": 1595601190.598,
"createdBy": "ckd0br26d00015csmbqeu11pe",
"modified": 1595601190.598,
"modifiedBy": "ckd0br26d00015csmbqeu11pe"
}
}
The access token should be kept in a separate stream in your mum’s account to enable her to easily retrieve your data. And if she has multiple children to monitor, she can add access tokens from her children’s accounts in this same stream (see “Store data accesses” section).

Each created access will generate a different token that can be shared with the concerned third-party (doctor, app, family, etc). Pryv.io supports three types of accesses: “personal”, “app”, “shared” that are hierarchically ordered (more information on accesses type here).
Perform an access delegation
Grandma Linda doesn’t master technology as well as her cookies recipe.
If she cannot connect on your app “Best Health App” to grant access to her data on a regular basis, you can facilitate it with an access delegation for your app. To do so, you can send an auth request to Linda at her first login to grant your app access to all or specific streams of her data (see here for more information on the auth request).
Linda’s stream structure:
└── Health
├── Sleep ("sleep/analysis" events)
├── Height ("length/cm" events
├── Glucose ("density/mmol-l" events)
└── Weight ("mass/kg" events)
At Linda’s login (and that’s the only moment when she will need to open the app), your app will make an auth request:
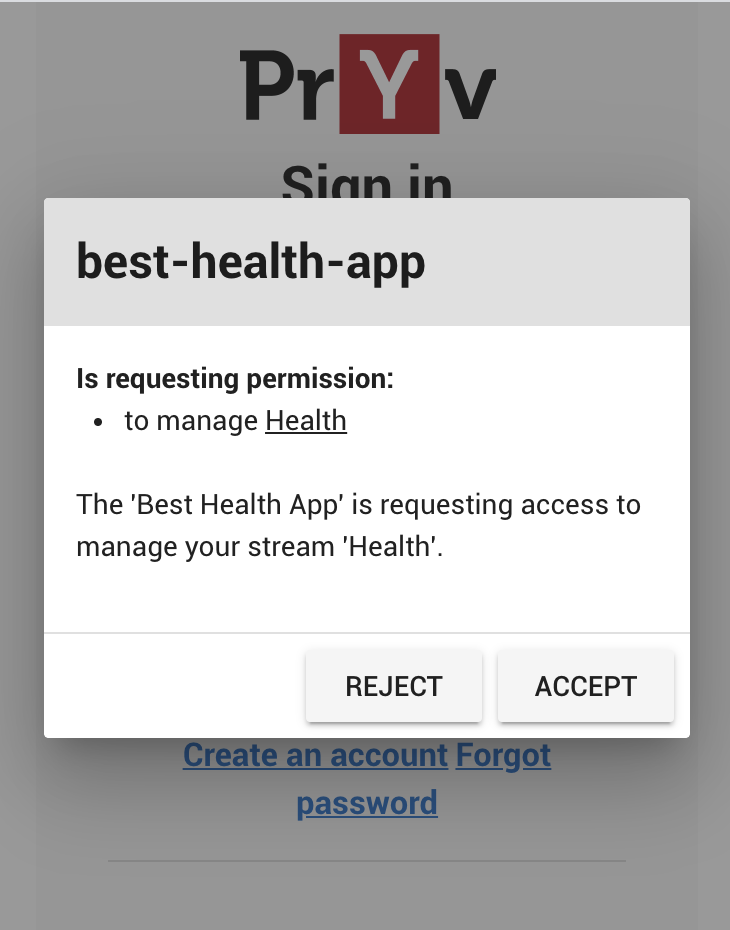
Once accepted by Linda, this will create the access for your app:
{
"access": {
"id": "ckdfruqs700067ppv03z7pef4",
"token": "ckdfruqs700077ppvk404g4bt",
"type": "app",
"name": "best-health-app",
"permissions": [
{
"streamId": "health",
"level": "manage"
}
],
"created": 1596535228.951,
"createdBy": "ckdfruqs700017ppvj4rci1cg",
"modified": 1596535228.951,
"modifiedBy": "ckdfruqs700017ppvj4rci1cg"
}
}
This works as a delegation of access, and the “app” token will be able to generate shared accesses whose permissions must be a subset of those granted to your app (here the stream “Health”).
For example, if your app needs to share the “Glucose” data from Linda with her doctor, it can do so by creating the following shared access:
{
"method": "accesses.create",
"params": {
"name": "For Linda's doctor",
"permissions": [
{
"streamId": "glucose",
"level": "read"
}
]
}
The resulting access:
{
"access": {
"id": "chjkzuit098567hjk97r2wer1",
"token": "czuifgh567128lkj098w2dg",
"type": "shared",
"name": "For Linda's doctor",
"permissions": [
{
"streamId": "glucose",
"level": "read"
}
],
"created": 1596535228.951,
"createdBy": "ckdfruqs700017ppvj4rci1cg",
"modified": 1596535228.951,
"modifiedBy": "ckdfruqs700017ppvj4rci1cg"
}
}

While Linda can still be making delicious cookies for you.
Store data accesses
Let’s take again the previous example where Grandma Linda provides your app an access to her data while she can still bake delicious cookies and not bother too much with technology.
Linda has delegated you access to her account, and you need to share the particular stream “Glucose” with her doctor Tom (see the example in previous section).
Stream structure for Grandma Linda:
└── Health
├── Sleep ("sleep/analysis" events)
├── Height ("length/cm" events)
├── Glucose ("density/mmol-l" events)
└── Weight ("mass/kg" events)
Where should her doctor keep the access token that will be generated for this sharing, along with other patients’ tokens ?
When Linda gives a “read” access to Doctor Tom on her stream “Glucose”, this will generate the access token “czuifgh567128lkj098w2dg”. This access should be kept in a dedicated stream, along with other patients’ tokens.
Stream structure for doctor Tom:
├── Personal profile
│ ├── Name ("name/id" events)
│ ├── Hospital ("name/id" events)
│ └── ...
└── Patient accesses ("credentials/pryv-api-endpoint" events)
Doctor Tom will need to keep all access tokens to his patients’ accounts in the dedicated stream “Patient accesses”.
Every time a patient grants him access to his data, the access token to his Pryv.io account will be saved in a credentials/pryv-api-endpoint event under the stream “Patient accesses” (see App guidelines for why we use this format).
In the case of Linda, the following event will be created in the stream “Patient accesses” of Doctor Tom:
{
"method": "events.create",
"params": {
"streamIds": ["patient-accesses"],
"type": "credentials/pryv-api-endpoint",
"content": "https://czuifgh567128lkj098w2dg@linda.pryv.me/"
}
}
To access Linda’s data, Doctor Tom will perform an events.get call on the stored Pryv API endpoint.
